Schrödinger’s Microservice
In a distributed system or microservices architecture, operations must be designed differently than in applications with traditional monolithic transactional storage. APIs in a microservices architecture are frequently complex, made up of many parts. State is scattered across various storage technologies, first-party components, third-party SaaS products, cloud databases, queues, and services.
What is frequently overlooked is that this property of state distribution puts microservices into the software equivalent of “quantum superposition,” where state appears to behave unintuitively.
I sometimes think of a software product as a physical thing, like a shovel, a door, or a plant. Software products and physical things both unlock some capability that its users wouldn’t otherwise have. Continuing that metaphor, the constellation of services that make a software product tick are like the molecules that give a physical thing its shape. The operations that make up the services are its atoms, which become useful only when linked together.
The data — the individual states scattered across the entire software system — are like the weird little subatomic particles that make up matter, both of which behave counterintuitively on inspection.

Like the spin properties of quarks and muons of the physical world, the state of data in the world of distributed software is not well defined at any moment in time. Designing a massive-scale distributed system is an exercise in herding Schrödinger’s cats; dependencies are simultaneously available and unavailable, databases simultaneously updated and not updated.
Below, I’ll discuss important design points of distributed systems, including atomicity, consistency, partial failure, and idempotency, as well as useful design and thought patterns to deal with all this weirdness at scale.
The major points I make below are:
- Building an atomic operation in a microservices architecture is difficult.
- Operations should model idempotency as an identifier of business intent.
- The availability of an operation is roughly the product of its dependencies.
Atomicity and Consistency
In software, the term “atomic” refers to being all-or-nothing. If any effect of an atomic multi-part operation doesn’t occur, none of the other effects should occur either.
Commonly, a “side effect” of an operation is a state change in a database, the creation of a file, a new message in a queue, etc., and an “operation” is a synchronous HTTP API.

A canonical example of an atomic complex operation is a banking transaction.
A Payer grants a Payee some Payment.
The bank transaction operation is made up of two parts:
a) add Payment to Payee
b) subtract Payment from Payer
Importantly, if any one part doesn’t occur then, neither part should, otherwise the system is not closed. Money is falsely “created,” from the ether, if addition succeeds but subtraction fails. Conversely, money “leaks away” if subtraction succeeds but addition fails.

This poses a problem for distributed systems of microservices. Since state is spread across many components, it’s hard to use tools like database transactions to achieve the desired atomic behavior.
A complex operation in a distributed system is only truly atomic if it’s impossible for clients to observe that it is the sum of many parts, that state is spread across many components.
Design public operations with one synchronous side effect
In my experience, the most commonly missed design consideration in microservices is partial failure. In complex public operations, those with multiple parts that can be called by clients outside of the service boundary, there should be a single synchronous side effect, and all other side effects should occur secondarily as a result of the first side effect.
Concretely, there should be exactly one state change in the synchronous path of public APIs. One new item in one table. One transaction across multiple tables. One remote call to one mutating remote dependency. Nothing more!
Durable threads
The reason operations should have exactly one state change deals with something I refer to as “Thread Durability.” A thread of execution is durable if there is some service-internal non-ephemeral mechanism that ensures all steps of the thread are executed. A thread of execution is not durable if it relies on some actor outside the service boundary to ensure that thread is completed if part of it failed previously.

Examples of non-durable execution threads include chained REST API calls: nothing will prevent a smart phone from losing its network between sequential API calls as it enters an elevator. Similarly non-durable but less obvious execution threads are Futures on the heap of JVMs, Promises in an NodeJS service, or any other state that is only represented in the memory of a host.
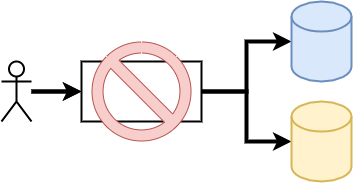
If the process can crash, the network can die, or any other of a million things can go wrong between sequential state updates, there is nothing guaranteeing that all desired updates will ever happen.

From a client perspective, no database is always reachable. No remote dependency has 100% availability. None! Even the most sophisticated, highly-available networks and redundant cloud services are unreachable sometimes. Sometimes your server crashes.
Furthermore, clients of public operations will do whatever they want, not what the designers of the service expect. Clients may or may not retry, so the service itself needs to protect its own state and ensure threads are completed.
At scale, ‘sometimes’ means ‘every day’. Build operations with failure at any moment in mind, and don’t depend on external actors for consistency.
Identity entities and Change Data Capture
Related to atomicity is consistency. Clients of an “eventually consistent” operation cannot observe that an operation was composed of many parts after some period of time.
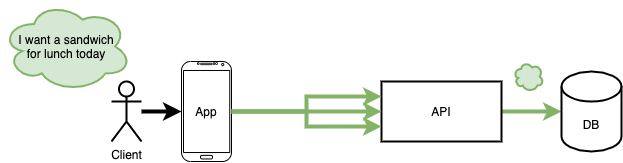
Eventual consistency is a useful tool to achieve the above type of “thread durability”. My preferred approach is the Change Data Capture (CDC) design pattern. In CDC, the database itself guarantees that the thread of execution is passed to some other component (i.e. a change handler) as a result of data being changed.
A “request”, “ledger,” or “identity” entity is created in a database, and a response is immediately sent back to the client. This response has just enough information for the client to have an id for the created entity, indicating with a status that its creation is ongoing, and enough data is stored for the rest of the system to eventually complete all parts of the thread.
After observing that data has changed, the CDC handler asynchronously completes all other parts of the thread.

CDC can be very easy to implement and doesn’t cost much, but can be a scary paradigm shift for a development team. CDC is available natively in many common databases, and implementations include MongoDB CDC, DynamoDB Streams, Kafka connectors, PostgreSQL CDC, etc. Many such integrations also guarantee that a change handler actually succeeds or the change is put into a dead letter queue if not.
An argument against this pattern is that it incurs a cost of additional complexity or latency due to eventual consistency.
In practice at scale, it’s better to be “always eventually consistent” than “occasionally never complete.” The contract is explicit, will eventually work itself out, is usually quick enough for most applications, and is a rough edge that can be engineered around.
Operations should be idempotent
When designing a complex operation, it’s useful to consider the effects on the system when any one sub-operation happens zero, one, or ten times in any order.
If designing for atomicity is dealing with a sub-operation happening zero times, then designing for idempotency is dealing with a sub-operation happening ten times.
An idempotent operation can be repeatedly invoked with the same input, but will only cause a single client-observable state change. All public mutating operations should be idempotent, because a client can (and will) retry as many times and as often as they want.
Typically idempotency is achieved by using a randomly generated unique request identifier and skipping requests that have already been performed. These identifiers go by many names, commonly called Idempotency Tokens, Client Tokens, Client Keys, Idempotency Keys, or occasionally Request Ids.
Model idempotency as intent
A good way to think about idempotency, and maybe even a better name for it, is an identification of intent. A client’s singular intent should correspond to a singular side effect. It follows that a singular intent should then have a single unique Intent Identifier (i.e. Client Token, Idempotency Token, etc).
Here intent means a physical or business gesture, such as my desire to buy a sandwich for lunch today because I’m hungry. My intent is not to “push the order sandwich button,” nor to “call the POST /sandwich API.” The business gesture — the thing that my belly cares about — is getting a sandwich, not at all what is involved in making that happen.
The most common mistake with the ‘token-based request de-duplication’ approach of idempotency is incorrectly choosing entropy to generate a random idempotent request identifier.
If an operation collects the entropy to generate such an identifier on the server side, then that operation is almost never actually idempotent. This is clear when you consider that after a client makes their request they might automatically retry due to a network hiccup. The service would generate request identifiers for both the original intent, but then also for the retries.
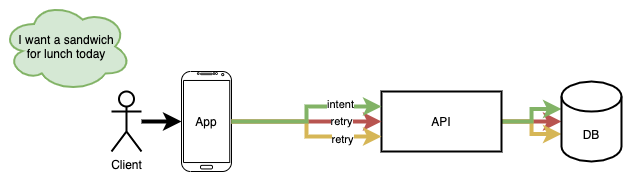
I like to think of an idempotent request identifier as a checksum of the inputs that went into a business decision. In that sense, operations should collect entropy used to randomly generate idempotent request identifiers in a way that maps as closely to intent as possible.
In the above example, a “SHA(shopping cart)” could be used as the seed for the “sandwich order idempotent request identifier”, because it contains a decent approximation of all the inputs of the business gesture (the user making an order, the session, the contents of the cart, the vendor, etc.).
Timeout is not the same as failure
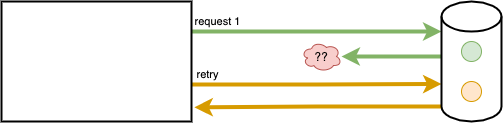
The most common motivation for this is the fact that a “network timeout” of a remote dependency is not the same as an explicitly modeled total failure. From the client’s perspective, the state on the server side after a client-side timeout is undefined.
When a dependent service or storage times out, a client cannot be sure if the service is busy processing the request, done processing the request, or never even got the request. A client cannot know whether a requested state change has happened on the server-side when a request times out. As light behaves like both waves and particles simultaneously, a timeout behaves simultaneously like failure and success.

This is a well-studied phenomenon called The Two Generals problem.
When implementing a timeout-reactive retry, consider that the system has the following possible states:
- A remote dependency was requested once, which was received once
- A remote dependency was requested twice, which was received once
- A remote dependency was requested twice, which was received twice
- A remote dependency was requested twice, which was never received
.. and so on.
Probabilistic failure
The availability of a complex operation is the multiplicative product of all dependencies’ minimum availabilities, assuming they themselves do not share dependencies. If any one dependency fails, the complex operation will fail.
Consider a complex operation with three synchronous remote dependencies: a cloud database, a SaaS service, and a first-party component. The cloud database could have 99.9% availability. The SaaS service has 99.9% availability. And the first-party component has 99.9% availability.
At first glance, the availability of the complex operation appears to be 99.9% — the availability of all three dependencies. However, this is not the case. If availability is the inverse of failure, and the probability of failure is the probability that any one of the three dependencies fail, then the maximum availability is 99.9% x 99.9% x 99.9% = 99.7%.
As a microservices architecture grows, and operations get more complex (i.e. more parts), consider that the maximum availability falls proportionally. As the number of dependent services grows past ten or more, which is common in service oriented architectures, availability quickly starts dropping some important nines.
Summary
If you’re working in distributed systems, consider what happens to your users if any part of an operation occurs zero, one, or ten times, or in any order.
Operations should model idempotency as an identifier of business intent
The probability of failure in a complex operation is the multiplicative product of the probability of failure of all components. The more dependencies you have, the less available your service can be.
Appendix, References
Two Generals
Part of the post was inspired Joey Lynch’s, “Distributed Systems Shibboleths”. Highly recommended reading 👌.
Editing
Thanks to Evan Wondrasek for editing!

